안녕하세요. 플러츠렛입니다.
얼마 전에 Chat GPT에게 코드 생성 부탁해본 적이 있습니다. 결과는 꽤 괜찮은 코드를 작성해주더군요.Cursor 라는 IDE를 사용해봤을 때 내가 어떤 코드를 작성할 지를 미리 예측하고 작성해주는 것도 경험해봤습니다.
이번에는 그런 코드를 생성해주는 AI 모델을 로컬에서 동작하게 구성하고, VS Code 확장 플러그인으로 연결해서 코드 작성 시 사용해보는 것을 목표로 해볼 생각합니다.
일단 사용할 AI 모델은 아래의 CodeT5 라는 모델이고, 코드 작성에 특화된 모델이라고 합니다.
Home of CodeT5: Open Code LLMs for Code Understanding and Generation
그리고 VS Code로 구성할 때 참고할 자료입니다.
지금 당장은 사전 지식이 없다 보니 어떻게 구성해야 하는 지부터 차근차근 알아가면서 진행해볼 예정입니다.
1개의 좋아요
일단 운영체제는 윈도우이고, wsl 등은 사용하지 않고 진행하겠습니다.
우선 파이썬을 최신 버전으로 설치했습니다. 가이드에서는 Colab을 이용하라고 되어 있지만, 저는 로컬에 구성하는 것이 목적이다 보니 파이썬으로 직접 구동할 예정입니다.
파이썬 최신 버전 다운로드 링크
마찬가지로 라이브러리 설치 역시 로컬으로만 동작하면 되니 ngrok 관련 설치도 넘어가겠습니다.
pip install fastapi uvicorn nest-asyncio accelerate
설치 과정에서 torch 관련 오류가 나왔고, 해결하기 위해 Cuda Toolkit를 설치하고, PyTorch의 공식 사이트에서 명령어를 가져와서 설치했습니다. torch가 이미 설치되어 있다면 넘어가도 좋습니다.
설치한 버전
Cuda Toolkit: 12.6
PyTorch: Preview (Nightly)
사용한 torch 설치 명령어
pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu126
Cuda Toolkit 다운로드 링크
PyTorch 공식 사이트
일단 설치할 건 이게 끝인 모양입니다. 다음으로 코드 작성으로 넘어가 보겠습니다.
1개의 좋아요
일단 허깅페이스에서 codet5p의 모델을 찾아 테스트 삼아 실행해보았습니다.
codet5p 770m
해당 모델 페이지에서 가져온 예시 코드인데, 환경이 구성된 후 파이썬으로 실행해보면
from transformers import T5ForConditionalGeneration, AutoTokenizer
checkpoint = "Salesforce/codet5p-770m"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = T5ForConditionalGeneration.from_pretrained(checkpoint).to(device)
inputs = tokenizer.encode("def print_hello_world():<extra_id_0>", return_tensors="pt").to(device)
outputs = model.generate(inputs, max_length=10)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
# ==> print "Hello World"
실행하면 print "Hello World" 출력되는 것을 확인했습니다.
그리고 참고자료의 코드를 재구성해서 아래와 같은 코드를 작성했습니다.
from transformers import AutoTokenizer
from transformers import T5ForConditionalGeneration
import torch
from fastapi import FastAPI
import uvicorn
import nest_asyncio
checkpoint = "Salesforce/codet5p-770m"
device = "cuda" # for GPU usage or "cpu" for CPU usage
max_length = 512
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = T5ForConditionalGeneration.from_pretrained(checkpoint).to(device)
app = FastAPI()
@app.post('/generate')
async def generate(request:dict):
# request 처리
parameters = request["parameters"]
inputs = tokenizer(request["inputs"], max_length=max_length, return_tensors="pt").to(device)
# # generate method에 사용되지 않는 parameter pop
return_full_text = parameters.pop("return_full_text")
# # 코드생성
outputs = model.generate(inputs, **parameters, max_length=max_length)
return_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
# text-generation-inference의 output format으로 맞춰 return
return {"generated_text":return_text}
nest_asyncio.apply()
uvicorn.run(app, host="0.0.0.0", port=8000, reload=False)
파이썬 코드를 실행하고 나서 서버가 실행됐다는 문구와 함께 http://0.0.0.0:8000 이런 링크를 출력했습니다. 오류 코드 없이 실행됐다면 다음 단계로 넘어가도 되겠습니다.
다음 단계는 vscode의 확장을 설치해서 AI 코드 자동 생성을 실제로 테스트 하는 것입니다.
1개의 좋아요
이제 VS Code에서 직접 사용해보기 위해서 llm-vscode라는 확장을 설치했습니다.
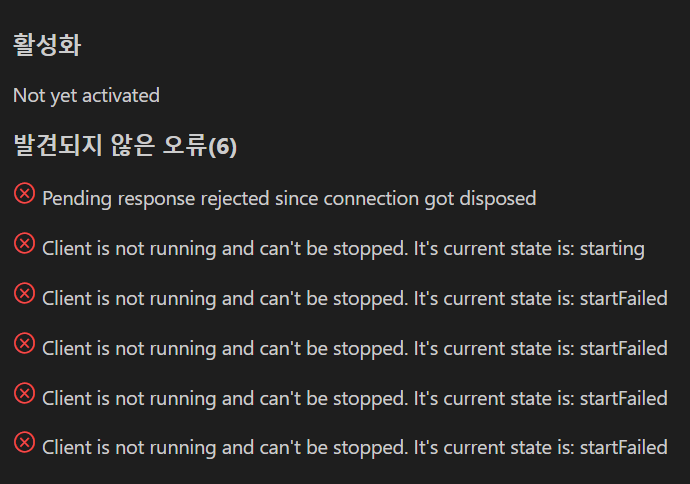
그런데 설치는 했으나 뭔가 제 환경에서는 제대로 동작하지 않았습니다.
확장 재설치, 설정 모두 지우기, /.vscode/extensions 경로에서 해당 확장 지우기 등 여러가지 방법을 시도해봤지만 결국 동작하지 않는다는 결과만 남았습니다.
일단 다른 확장을 찾아서 다시 한 번 시도해 봐야겠습니다.
2개의 좋아요